Most AI projects don't fail because the model was wrong.
They fail because teams obsess over the algorithm — and nobody solves what comes after it.
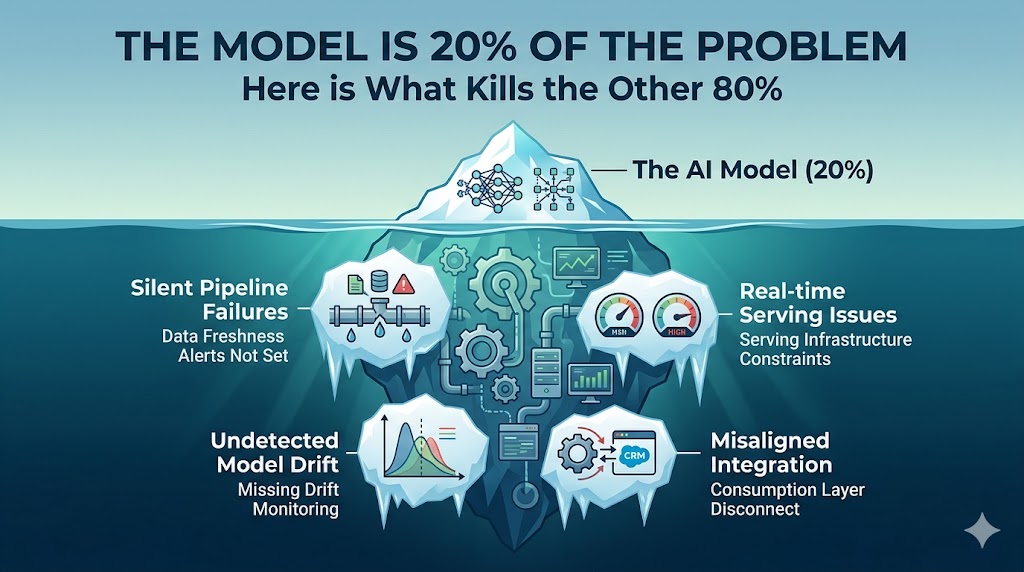
After 10+ years shipping ML systems at AWS, WooliesX, and Linkby, here is what actually kills AI projects in production.
1. Silent Pipeline Failures
The pipeline breaks at 3am. No alert. No error. The model scores on stale data for six days before anyone notices the predictions stopped making sense.
This is the most common failure mode I have seen across every organisation I have worked with. The model gets all the attention during development. The pipeline that feeds it gets bolted on at the end. It works in staging. It breaks in production in a way nobody anticipated.
The fix: treat pipeline monitoring as a first-class deliverable, not an afterthought. Alert on data freshness, not just model errors.
2. Real-time Serving Issues
The feature store works flawlessly in the notebook. Then you try to serve it at scale and discover your latency is 4 seconds. The product team needed 200 milliseconds. Back to zero.
I lived through this at WooliesX. We built beautiful models in offline evaluation. Moving to real-time serving on millions of customers required rebuilding the feature engineering layer entirely. The model was never the bottleneck — the infrastructure was.
The fix: design for serving latency requirements from day one. Build your feature store with production constraints in mind, not batch processing constraints.
3. Undetected Model Drift
Customer behaviour shifted three months ago — but nobody built monitoring. The model is still optimising for a world that no longer exists. Your stakeholders just think the model is bad.
At Linkby, I built drift monitoring into the platform from week one. Not because I expected drift — because I knew it was inevitable. Every production model drifts. The question is whether you catch it in three days or three months.
The fix: agree on drift thresholds and alerting before deployment. Set up automated retraining pipelines where the business case justifies the cost.
4. Misaligned Integration
The stakeholders needed insights in Salesforce. You built a beautiful API. Nobody told you the sales team does not use APIs. Six months of work. Zero adoption.
This one hurts because it is entirely preventable. The technical work is often excellent. The failure is in not asking the right questions early enough — how will this actually be consumed, by whom, in which system, in what format.
The fix: start with the consumption layer, not the model. Work backwards from where the output needs to live.
The rule that changes everything
I have watched teams spend a year perfecting a model that never shipped. I have also watched scrappy teams get a good enough model into production in six weeks and generate millions in revenue.
Why? Because they followed one rule: treat your infrastructure as seriously as your algorithm.
The model is maybe 20% of the problem. The other 80% is what separates the teams that ship from the teams that demo.
What has killed an AI project in your organisation — and was it ever actually the model? I would genuinely like to know. Drop a comment on LinkedIn.
